DynaGuide: Steering Diffusion Polices with
Active Dynamic Guidance
Neural Information Processing Systems (NeurIPS) 2025
Maximilian Du1 Shuran Song1
1 Stanford University

arXiv
Code
Video Overview
What is DynaGuide?
Can we steer a pretrained robot policy without changing weights, sampling excessively, or requiring goal conditioning?
We present a novel policy steering approach, DynaGuide, that accomplishes this. DynaGuide works with any diffusion policy by influencing the action diffusion process with an expressive guidance signal. This guidance can steer diverse policies to one behavior, multiple behaviors, and even avoid behaviors. In our experiments, we show that DynaGuide is robust and offers advantages in performance and features compared to relevant baselines. We also show that DynaGuide works on off-the-shelf policies with a real robot.
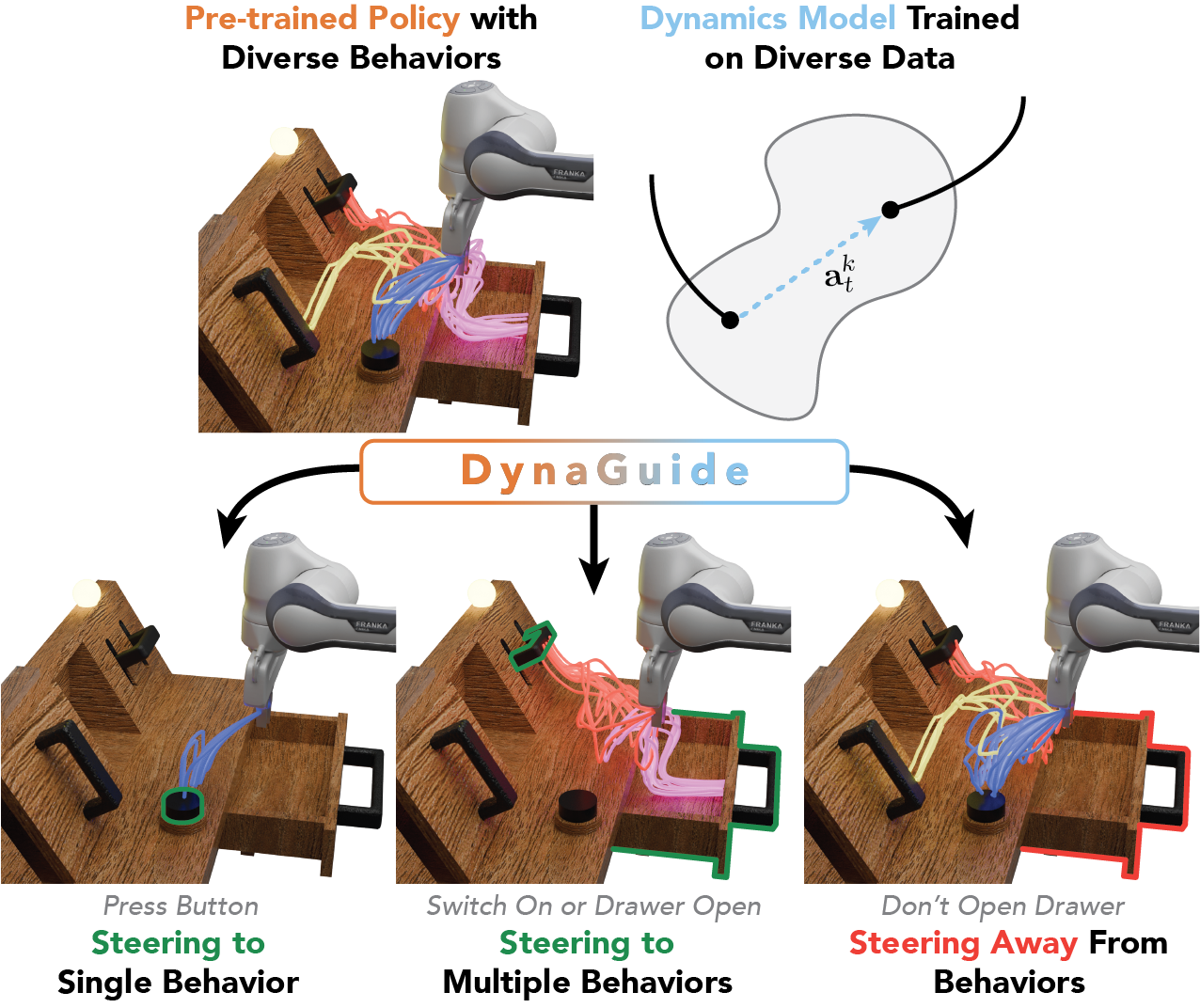
How does DynaGuide Work?
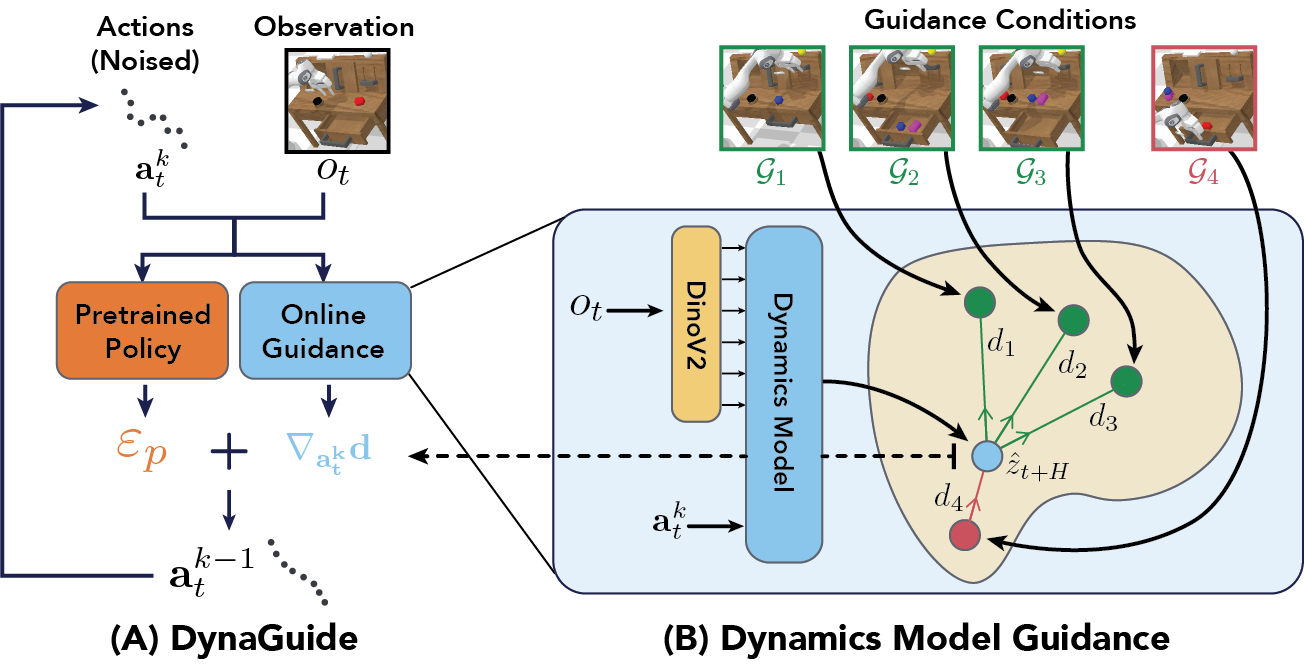
DynaGuide has two components: 1) the latent dynamics model and 2) the diffusion guidance. During inference-time, we supply DynaGuide with a set of guidance conditions: desired outcomes and undesired outcomes, all as visual observations.
The latent dynamics model predicts a future outcome based on the robot's current visual observation and proposed action. We use latent distance to compare this future outcome to the embeddings of the guidance conditions: visual observations of desired / undesired outcomes (B).
This distance creates a differentiable metric that tells us how to change the current actions to better meet the guidance conditions. We add this gradient to the noise prediction of the base policy in the action diffusion process (A).

DynaGuide on a Toy Example: In this toy example where the base policy navigates to any colored square, DynaGuide is able to steer the agent towards the blue square. DynaGuide works with the base policy to find a mode that best satisfies the guidance conditions.
Results: Simulation
DynaGuide can Steer Policies to Individual Behaviors
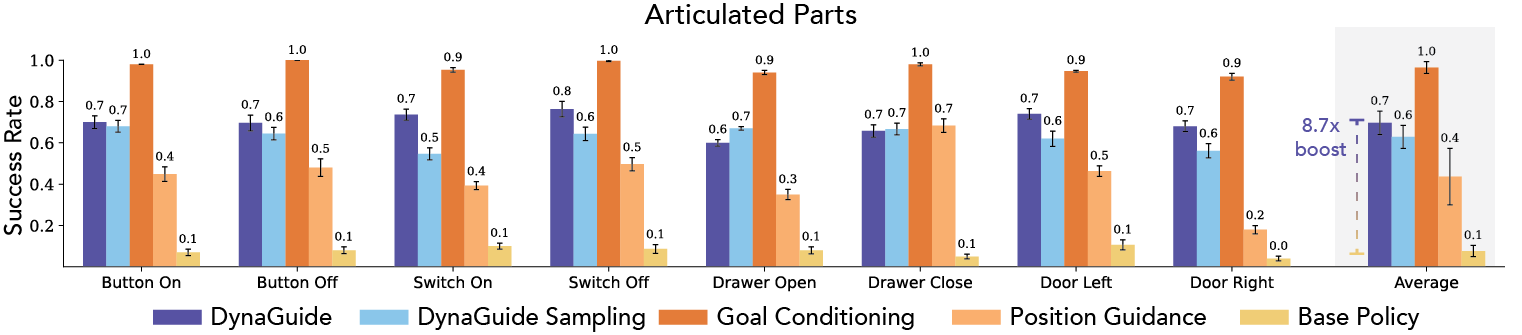
In the CALVIN environment, DynaGuide can take a diverse base policy and steer it to a target behavior with an average success rate of 70%, on behaviors involving articulated parts (like drawers, switches, and buttons). It outperforms the DynaGuide-Sampling baseline, which samples from the unaltered base policy and uses the same dynamics model to pick the best action. It also outperforms a Position Guidance method that uses diffusion guidance to steer the robot to a keypoint in space. However, a specially-trained goal-conditioned policy will perform nearly perfectly in this setup, which is expected.
So, what happens when the guidance conditions are less perfect?
DynaGuide Remains Robust to Lower-Quality Objectives
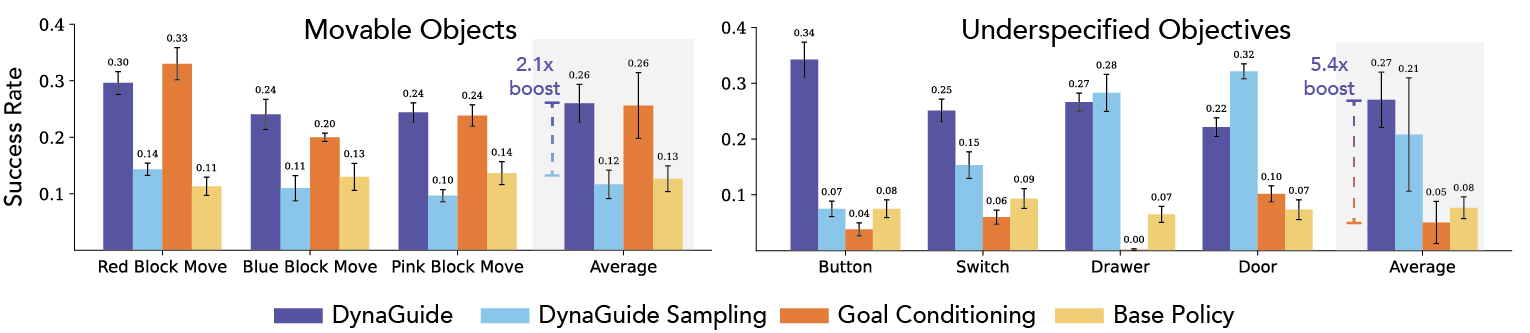
Clean guidance condition images may be hard to collect when the environment is dynamic. When we try to steer the base policy towards movable objects (colored cubes, left graph), the guidance condition images might be conceptually similar but visually distinct, because the cubes can be arranged anywhere. All performances drop, but the sampling baseline and goal conditioned baseline are affected more than DynaGuide. This effect is even more pronounced when guidance conditions images randomize the states of everything other than the target object (right graph). As the guidance condition images become lower in quality, goal-conditioned baselines become out of distribution and drop quickly in performance. DynaGuide is still affected, but the strong latent dynamics model ensures its robustness.
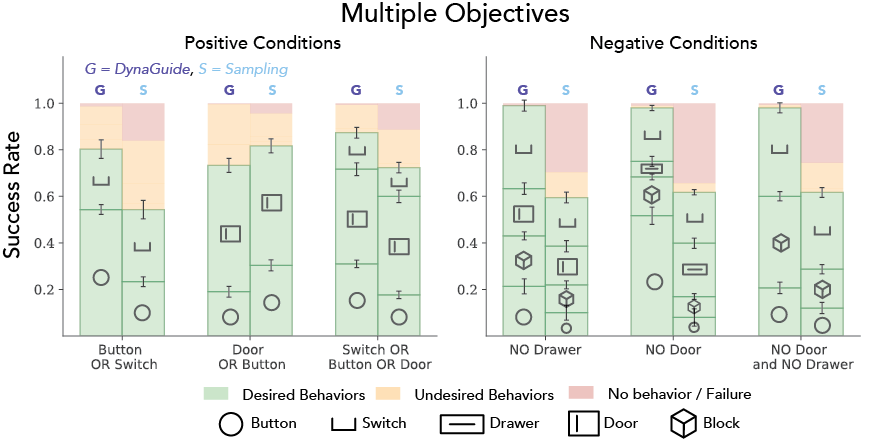
DynaGuide can Steer with Complex Objectives
Sometimes steering a policy means accepting multiple behaviors or avoiding other behaviors. DynaGuide uses latent distances to guidance conditions, so it can leverage sets of guidance conditions representing multiple acceptable and unacceptable behaviors. DynaGuide's active guidance performs better on these complex objectives than sampling approaches.
DynaGuide Enhances Underrepresented Behaviors
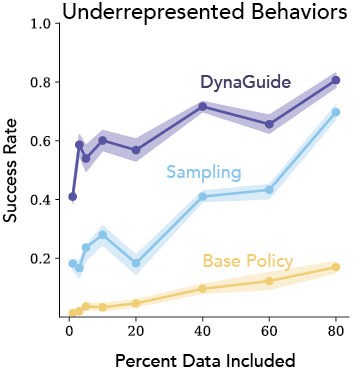
Not all behaviors are equally represented in the training set of the base policy. Sampling approaches can boost the likelihood of a rare behavior, but it is still affected by the likelihood of the correct action being sampled by the base policy. Active guidance in DynaGuide allows the dynamics model to seek rare behaviors directly in the diffusion process, leading to a 40% steering success rate on a behavior that is represented by only 1% of the training data.
Results: Real Robot
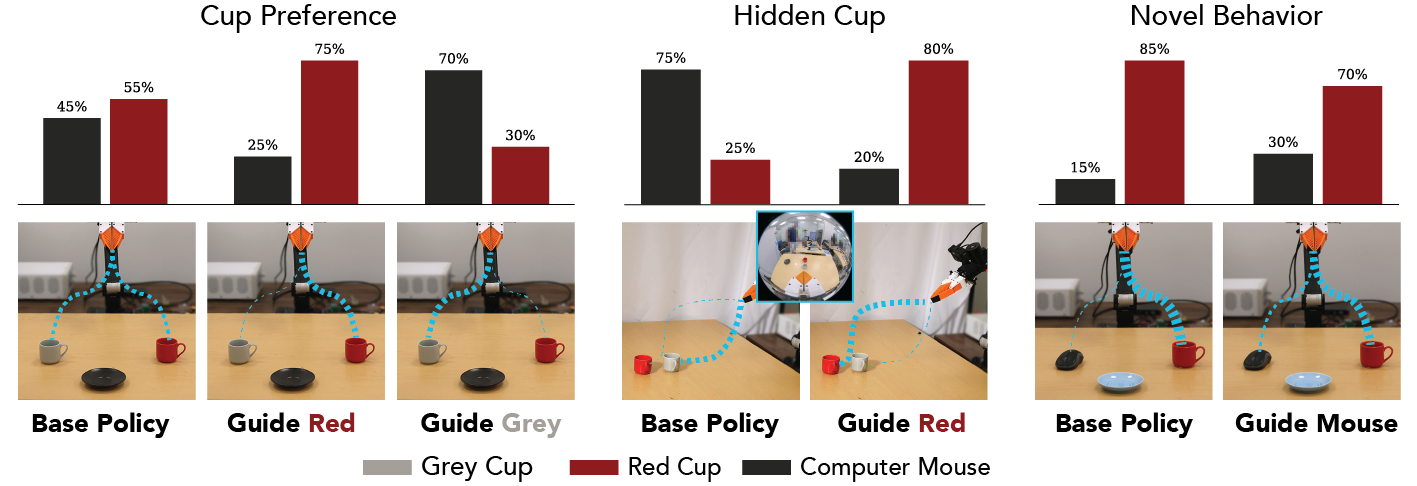
Unlike goal conditoning and other specially-trained policies, DynaGuide can work on top of any diffusion policy. We test this by steering an off-the-shelf cup arrangement policy to express color preference and even to interact with a novel object. Below, we show individual videos and results.
Expressing Color Preference on a Real Robot
We present the robot with a choice of two different colored cups equidistant from the robot. The base policy does not have a color preference, but DynaGuide is able to steer this policy towards majority grey cups and towards majority red cups.
Base Policy: 55% Red Cup, 45% Grey Cup
Guide to Red: 75% Red Cup, 25% Grey Cup
Guide to Grey: 30% Red Cup, 70% Grey Cup.
Seeking Underrepresented Behaviors on a Real Robot
We place a red cup directly behind a grey cup. The base policy typically grabs the closest cup, but DynaGuide is able to coax the base policy to move past the close grey cup and grab the red cup.
Base Policy: 25% Red Cup, 75% Grey Cup
Guide to Red: 80% Red Cup, 20% Grey Cup
Seeking Novel Behaviors on a Real Robot
We give the robot a choice between a red cup and a computer mouse. The base policy is trained only on cups, so it generally avoids the novel object. The dynamics model is trained on a larger datset of interactions including computer mice, so it can steer the robot to double the number of interactions with the novel object.
Base Policy: 85% Red Cup, 15% Mouse
Guide to Mouse: 70% Red Cup, 30% Mouse
Cite this Paper
@inproceedings{du2025dynaguidesteeringdiffusionpolices,
title={DynaGuide: Steering Diffusion Policies with Active Dynamic Guidance},
author={Maximilian Du and Shuran Song},
booktitle={Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS)},
year={2025}
}Acknowledgements
Maximilian Du is supported by the Knight-Hennessy Fellowship and the NSF Graduate Research Fellowships Program (GRFP). This work was supported in part by the NSF Award #2143601, #2037101, and #2132519, Samsung's LEAP-U program, and Toyota Research Institute. We would like to thank ARX for the robot hardware and Yihuai Gao for assisting with the policy deployment on the ARX arm. We appreciate Zhanyi Sun for discussions on classifier guidance and all members of the REAL lab at Stanford for their detailed feedback on paper drafts and experiment directions. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.
The Calvin Experiments were made possible with the Calvin benchmark codebase. The diffusion policy was adapted from the Robomimic repository. The dynamics model was inspired by the Dino-WM implementation and leverages representations from Dino-V2.